

はじめに
午後8時、クライアントから「画面が真っ白です」と連絡が入る。
判断は1分単位、報告先は5方向、手は2本しかない。
そのとき、チームは最初の15分で何をすべきか——即答できますか?
この記事は、発生から第一報・暫定対応・根本原因の特定・障害報告書の提出まで、一気通貫で動くための手順とテンプレートです。
第一報フォーマット・障害報告書・体制表はそのままコピーして使えます。
全体の流れ
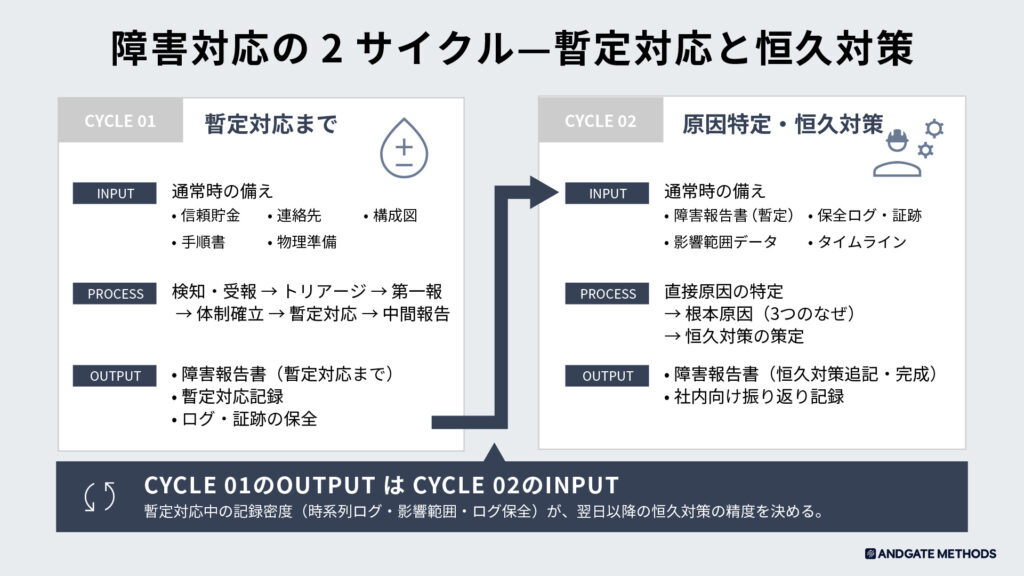
本記事は2つのサイクルで構成しています。
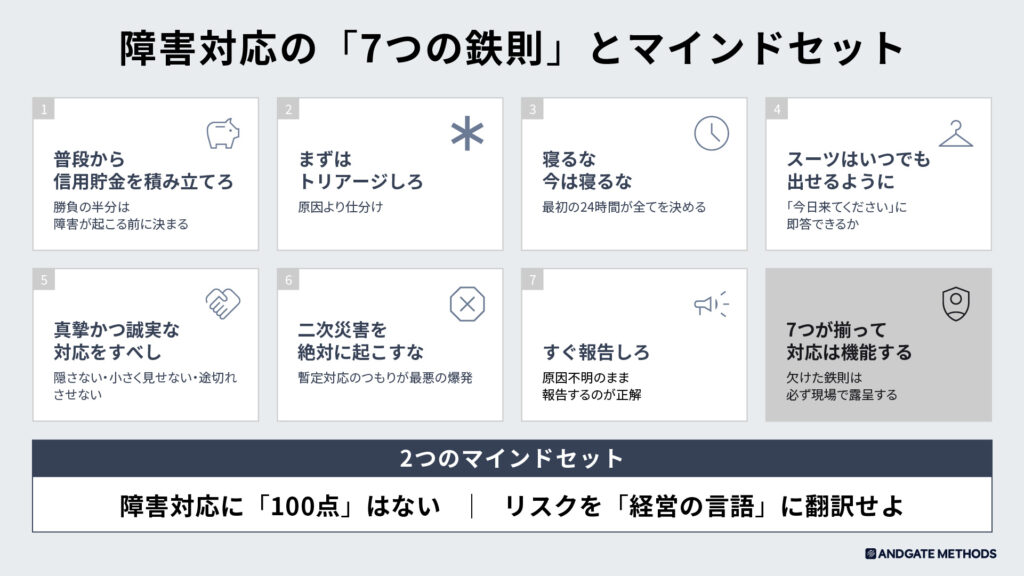
7つの鉄則
第1サイクル:暫定対応まで
INPUT 平時の備え
障害が起きてから「あれどこだっけ」では遅い。
以下を平時から最新化し、いつでもアクセスできる場所に置いておくこと。
障害対応で最も辛いのは技術的な難しさではありません。
「この人たちに任せて大丈夫なのか?」という目で見られながら対応することです。この消耗戦を避けるのが、日常の信頼貯金です。
信頼貯金の本質は、誠実かつ真摯に、プロジェクトのことを自分ごととして考え、能動的に提案・発言・行動ができているかどうかです。
受け身で言われたことだけをこなすチームに、障害時の裁量は与えられません。
信頼貯金
準備物を揃えること自体も信頼の一部ですが、それ以前に普段の行動で積み上がるものがあります。
以下を日常的にできているか、定期的にチームで振り返ること。
報連相
- 週次・日次の定例報告を欠かさず実施しているか。
- 進捗が遅れている場合、遅れが確定する前に自分から報告しているか。
- 顧客からの質問・依頼に対し、24時間以内に一次回答(調査中の旨でも可)を返しているか。
- 課題やリスクを検知した時点で、指示を待たずに自ら共有しているか。
小さな障害での立ち回り
- 軽微な不具合やヒヤリハットでも、検知したら顧客に報告しているか。
- 「影響が小さいから報告しなくていい」という判断をチーム内で黙認していないか。
- 小さな障害でも原因と対策を記録し、再発防止に繋げているか。
約束を守る
- 「〇日までに回答します」と言った期日を守っているか。(守れない場合は事前に連絡しているか)
- 会議で決まったアクションアイテムを期限内に完了しているか。
- Slack・メール・チケットのメンションに対し、既読スルーせず反応しているか。
物理的準備
「明日来てください」が「今日来てください」に変わります。
「行けます」と即答できる状態を常に保ってください。
- スーツ(クリーニング済み)
- 名刺(十分な枚数)
- 充電器・モバイルバッテリー
- PC+VPN接続確認済み
- 顧客オフィスへの経路と入館手段(入館証・受付電話番号)
システム情報
- システム構成図(最新版)——サーバー・ネットワーク・外部連携の全体像
- 監視ダッシュボードのURL一覧——CloudWatch・Datadog・Grafana等
- ログの確認方法——どこに何のログがあるか・アクセス手順(踏み台SSH、ECS Exec等)
- 切り戻し手順書——デプロイの戻し方・DB変更の巻き戻し方・手順と所要時間の目安
連絡先・体制
- 顧客側の緊急連絡先(電話番号・メールアドレス)——担当者・上長・夜間連絡先
- 自社側の障害対応メンバーリスト——名前・役割・電話番号・対応可能時間帯
- エスカレーション先一覧——誰にどの順番で連絡するか、判断基準(影響ユーザー数・売上影響等)付き。
PROCESS 検知から暫定対応・中間報告まで

検知・受報(発生から5分以内)
原因がわからなくても、影響が確定していなくても、まず報告しろ。
「もう少し調べてから」が一番の敵です。
報告が遅れるほど、顧客の不信は加速し、「隠していたのではないか」という疑念は後から拭えません。
- 報告内容をそのままメモする——「いつ・誰から・何が起きていると言われたか」
- 報告元に「受け取りました。確認中です」と即返信する(所要1分)
- 監視ダッシュボードを開き、アラートの有無を確認する。
- 自社側の障害対応リーダーに電話する(チャットではなく電話)
トリアージ(発生から15分以内)
障害を検知した瞬間、最初にやるのは原因調査ではありません。
何が起きていて、誰が影響を受けていて、今すぐ何をすべきかを仕分ける。
この仕分けなしに動くと、全員がバラバラに原因を探し始め、報告が遅れ、暫定対応が後手に回ります。
以下の3つの問いに答える。
推測ではなく事実だけを集める。
Q1. 何が起きているか(症状の確認)
- エラー内容を画面キャプチャまたはログから転記する。(推測ではなく事実のみ)
- いつから発生しているか、発生時刻を特定する。
- 今も継続中か、断続的か、すでに収まったかを確認する。
Q2. 誰がどれくらい影響を受けているか
- 影響を受けているユーザー数・顧客数を概算する
- 業務への影響レベルを判定する
- 完全停止
- 一部機能不可
- 性能劣化
- 表示不具合
- 売上・取引への影響があるかを確認する
Q3. 今すぐ何をすべきか(初動方針の決定)
- 暫定対応(切り戻し・縮退運転・機能停止)が必要か判断する。
- 暫定対応が必要な場合、手順書を確認し実行可否を判断する。
- 情報収集フェーズで十分か(影響が軽微な場合)を判断する。
原因不明のまま報告するのが正解です。
第一報(発生から30分以内)
事実を隠さない。
影響を小さく見せない。
影響を矮小化する意図が透けた瞬間、あとで直接対面した際に信頼は壊滅します。
誠実さは言葉ではなく行動で示すもの——深夜であろうと休日であろうと障害が続く限り対応を止めないこと、進捗がなくても報告を途切れさせないこと、これが誠実さの具体形です。
原因不明でも報告する。
以下のフォーマットをコピーして埋める。
- 発生日時:YYYY/MM/DD HH:MM (JST)
- 検知経緯:監視アラート検知 / お客様からの申告
- 事象:(例:〇〇画面においてエラーが発生し、一部機能が利用不可な状態)
- 影響範囲:全ユーザー / 特定テナント / 推定N名
- 現在の状況:調査中 / 暫定対応実施中
- 次回報告予定:(例:1時間後の HH:MM に中間報告を送付予定)
- 上記フォーマットで顧客に送付する——重大障害の場合は電話+メール(チャットだけは不可)
- 自社内の関係者(上長・営業)にも同内容を共有する。
- 次回報告の時刻を必ず明記し、守る。
報告の遅延(「もう少し調べてから」は禁句)、影響の矮小化(小さく見せる意図が透けた瞬間、信頼は壊滅する)、推測の事実化(「おそらく〜」を断定形で書かない)
体制確立(第一報と並行)
「全員で原因調査」は最悪。以下の4役を割り当てる(兼任可、ただし指揮者と対応者は分ける)。

- 体制表をチャットまたはドキュメントに明記する
- 連絡用チャンネル(Slack等)を障害対応専用で開設する
- 時系列ログの記録を開始する
(テンプレート:`HH:MM|誰が|何をした|結果`)
体制の宣言も誠実さ(鉄則⑤ 真摯かつ誠実な対応をすべし)の表れです。
「専任チームを組成し、収束まで最優先で対応します」と顧客に伝えることで、本気度が伝わります。
暫定対応(体制確立後すみやかに)
暫定対応のつもりが新たな障害を生む、これが障害対応における最悪のシナリオです。
障害後に再度障害を起こしてしまったら、積み上げた信頼貯金は一瞬でなくなります。
焦って打った暫定パッチが別の機能を壊す。
切り戻し先が安全でない状態に戻す。
影響範囲を狭く見積もったまま「復旧済み」と報告し再発する。
時間がないときこそ、一呼吸おいてください。
「完璧な復旧」より「被害の拡大防止」を優先する。
暫定対応実行手順
- 暫定対応方針を指揮者が決定する(切り戻し/縮退運転/機能停止/ワークアラウンド)
- 暫定対応手順を対応者と指揮者の2名で読み合わせ確認する
- 以下の安全チェックを実行する(二次災害防止)
- 暫定対応を実行する。
- 暫定対応後、症状が解消されたことを確認する。
- 顧客に暫定対応完了の報告をする
暫定対応前の安全チェック(1つでもNGなら暫定対応方針を見直す)
- 切り戻し先のバージョン/状態は安全か。(DBスキーマの差異等)
- 切り戻しの影響範囲は把握できているか。(他機能への副作用)
- 暫定パッチの場合、変更箇所以外への影響はないか。
- 手順を2人以上でレビューしたか。
- 本番実行前にステージングまたは手順の読み合わせで確認したか。
焦りと疲労が蔓延する時期は、障害対応以外の作業からも二次災害が生まれる。
障害対応期間中は通常作業も複数人レビューを必須とし、本番環境への変更は障害対応に直接関係するもの以外は凍結する。
中間報告(暫定対応後、または定期的に)
沈黙は不信を生む。進捗がなくても報告する。(鉄則⑤ 真摯かつ誠実な対応をすべし)
- 報告日時:YYYY/MM/DD HH:MM (JST)
- 現在の状況:(例:暫定対応実施完了 / サービス復旧済み / 根本原因の調査を継続中)
- 原因(判明している範囲):(例:〇〇コンポーネントの△△処理でエラーが発生。詳細調査中)
- 対応内容:(例:HH:MMに切り戻しを実施し、正常稼働を確認)
- 今後の予定:(例:根本原因の特定 → 恒久対策の策定 → 障害報告書の提出)
- 次回報告予定:(例:明日 HH:MM に続報を送付予定)
- 報告間隔を顧客と合意する(例:1時間ごと・半日ごと)
- 合意した間隔を必ず守る——進捗がなくても「継続中」と報告する
お問い合わせ メソッドの適用やプロジェクトの推進のご相談はこちら。
OUTPUT 第1サイクルの成果物
最初の24〜48時間の密度が、あとの1ヶ月を決めます。
これは体力論ではなく、誠実さの話です。
「今日はもう遅いから明日やろう」は禁句です。
翌日には記憶もログも劣化していることを忘れないでください。
暫定対応が完了したら、48時間以内に以下を揃える。
これが第2サイクル(原因特定・恒久対策)のINPUTになる。
障害報告書(暫定対応まで)
紙で出すことを前提に書く。
URLはプレーンテキストで記載する。
この時点では暫定対応までを記載し、恒久対応は第2サイクルで追記する。
- 【概要】:(障害の要約を1〜2文で。何が起きて、どう対応し、現在どうなっているか)
- 【発生日時】:YYYY/MM/DD HH:MM(JST)
- 【判明日時】:YYYY/MM/DD HH:MM(JST)
- 【復旧日時】:YYYY/MM/DD HH:MM(JST)
- 【発生事象】:(何が起きたかを具体的に。エラー内容・画面の挙動・ユーザーへの見え方)
- 【影響範囲】:(影響を受けたユーザー数・機能・期間 数値で示す)
- 【経緯】:
・HH:MM 〇〇を検知
・HH:MM 暫定対応を開始
・HH:MM サービス復旧を確認 - 【暫定対応】:(暫定対応として実施した内容と、その効果。制約事項があれば併記)
- 【直接原因】:(判明している範囲で記載。未確定の場合は「調査中」)
- 【根本原因】:後日追記予定
- 【恒久対策】:後日追記予定
- 【対策スケジュール】:後日追記予定
暫定対応記録
- 暫定対応の内容——何をしたか。(例:v1.2.3へ切り戻し、〇〇機能を一時無効化)
- 暫定対応の効果——症状は解消されたか、副作用はないか。
- 暫定対応の制約——この状態で何ができて何ができないか。(例:〇〇機能は利用不可のまま)
- 暫定対応の解除条件——いつ・何をもって暫定状態を終了するか。
ログ・証跡の保全
- アプリケーションログを取得・保存した(ローテーションで消える前に)
- インフラログ(CloudWatch Logs・アクセスログ等)を取得・保存した
- デプロイ履歴・変更履歴を記録した
- 影響範囲を数値で確定した(影響ユーザー数・機能・期間)
中間報告
- 顧客に中間報告を送付した(フォーマットはPROCESSセクション参照)
第2サイクル:原因特定・恒久対策
INPUT 第1サイクルの成果物を引き継ぐ
第1サイクルで揃えた以下の資料が、原因特定・恒久対策のインプットになる。
不足があれば先に補完する。
- 対応タイムライン——いつ何が起きて、いつ何をしたかの時系列
- 保全済みログ・証跡——アプリケーションログ・インフラログ・デプロイ履歴
- 暫定対応記録——何をしたか・効果はあったか・制約は何か
- 影響範囲データ——影響ユーザー数・機能・期間の確定値
- トリアージ時の記録——最初に観察された症状・影響レベル判定の根拠
PROCESS 原因特定から恒久対策まで
直接原因の特定
原因調査でも同じ姿勢が必要です。
推測ではなく事実を集める。
いきなり「おそらくこうでしょう」と仮説を固めにかかると、不都合な事実を見逃します。
タイムラインとログを突き合わせ、事実を積み上げてからメカニズムを言語化してください。
「何が壊れたか」を明らかにする。
- タイムラインとログを突き合わせ、障害が発生した正確なポイントを特定する。
- 障害直前の変更(デプロイ・設定変更・データ投入等)を洗い出す。
- エラーの発生メカニズムを技術的に説明できる状態にする。
根本原因の特定
誠実さは顧客対応だけでなく、社内の自己分析にも必要です。
「あの人がミスした」で終わらせた瞬間、改善は止まります。
人を責めず、「なぜそのミスが通ってしまうシステムだったのか」を修飾なく見つめることが、真の再発防止に繋がります。
「なぜ壊れたか」を深掘りする。人ではなく仕組みの穴を探す。

恒久対策の策定
「気をつけます」は対策ではない。仕組みで防げないものは対策として不十分。
技術的対策(コード・インフラ・監視の変更)
- 直接原因に対する修正内容を明確にする
- 同種の問題を検知する監視・アラートを追加する
- テスト(ユニットテスト・負荷テスト等)でカバーする
プロセス的対策(手順・レビュー・体制の変更)
- どの手順・ルールを追加・変更するかを明確にする
- レビュー体制の強化が必要か判断する
- ドキュメント(手順書・チェックリスト等)の更新箇所を特定する
スケジュール
- 各対策の実施予定日と担当者を決定する(WBS等ドキュメントとして作成)
- 対策完了の確認方法(どうなったら「対策済み」とするか)を定義する
- 顧客にスケジュールを提示する
策定した対策をひとつずつ見直し、「担当者が退職しても機能するか?」の問いが効果的。
人の注意力に依存する対策は、仕組み化するか、仕組み化できない理由を明記する。
OUTPUT 最終成果物
障害報告書(恒久対策を追記して完成)
第1サイクルで作成した障害報告書に、以下の項目を追記して完成させる。
- 直接原因——技術的に何が壊れたか(例:〇〇テーブルのインデックス欠損によるクエリタイムアウト)
- 根本原因——なぜ起きたか(例:リリース時のDBマイグレーション手順にインデックス作成が含まれていなかった)
- 恒久対応——再発防止のために実施する対策、技術的対策とプロセス的対策の2軸で記載。
- 対策スケジュール——各対策の実施予定日と担当者
- 全項目が埋まっていることを確認し、顧客に提出する。
振り返り記録(社内用)
今回の障害対応で得た学びは、次回の信頼貯金の原資です。
「よくやった」で終わらせず、チーム内で振り返り、平時の備え・判断基準・手順書を更新してください。
次の障害時に「このチームなら任せられる」と思われるかは、ここで決まります。
顧客提出用の障害報告書とは別に、社内向けの振り返りを残す。
これが次の障害に備える信頼貯金(鉄則①)になる。
- 対応の良かった点——次回も再現すべきこと(例:第一報が10分以内に出せた)
- 対応の悪かった点——次回改善すべきこと(例:切り戻し手順書が古く、確認に時間がかかった)
- 準備の不備——平時に整備しておくべきだったもの(例:連絡先リストが最新化されていなかった)
- INPUTの更新——第1サイクルの「INPUT(平時の備え)」セクションを、今回の教訓で更新する。
LOGIC COMMENT ANDGATEとしての意味
どれか1つが欠けても、対応は破綻します。
DOWNLOAD CONTENT
現場が燃えたとき、誰がやっても一定品質の対応ができる【Claude 専用スキル】を無料配布!

「障害対応の鉄則」メソッドをそのまま実行するスキルです。「障害対応して」の一言でガイドモードが起動し、現在のフェーズ(平時・発生中・暫定対応後・根本原因調査中・振り返り)をヒアリングして必要なモードを自動連結します。
平時準備のチェックから、5分で障害報告書ドラフト完成、なぜなぜ分析による根本原因の深掘り、顧客提出前の自動採点まで、障害対応の全フェーズを1つのスキルでカバーします。
【配布内容】methods_ME-008_incident.zip
- incident-response
- SKILL.md(スキル本体)
- README.pdf(利用ガイド)
- templates
- incident-report.md(障害報告書テンプレート)
- first-report.md(第一報テンプレート)
- interim-report.md(中間報告テンプレート)
- retrospective.md(振り返り記録テンプレート)
- precheck-results.md(平時準備チェック結果テンプレート)
- references
- 7-principles.md(7つの鉄則)
- precheck-items.md(平時準備チェック項目一覧)
- process-checklist.md(プロセスチェックリスト(フェーズ別))
- scoring-rubric.md(障害報告書採点ルーブリック)
- why-why-method.md(なぜなぜ分析メソッド)
※本スキルはClaude専用の「AIエージェント構築セット」です。他AIでは設計通りの動作にならない場合があります。
※生成AIの特性上、回答の正確性は保証されません。本ツールの利用により生じた不具合・損害・法的トラブル等について、当社は一切の責任を負いかねます。